CPU Arch Optimizations
Published:
Introduction
最近在读 Performance Analysis and Tuning on Modern CPU, 写点笔记.
这本书的作者是 Intel 的工程师, 所以主要涉及 Intel X86 CPU 的架构和优化, 而不包括 ARM 等其他架构.
本书内容不超过单个cpu插槽, 既不涉及 NUMA, 异构计算, MPI 等多节点多机的内容.
性能分析
Noise
CPU 性能分析中, 有许多环境是无法控制的, 可能来自硬件, 也可能来自软件.
- CPU的频率调节. 具体来说, 现代 CPU 都有动态频率调节(DFS), “冷”的时候会自动超频, “热”的时候会降频.
- software的cache
- UNIX的环境大小(存储env var的bytes数)和给linker提供目标文件的顺序都会以不可预测的方式影响性能.
- 内存布局: 内存布局带来的影响可以通过运行时重复的随机化代码, 堆栈和堆对象的放置来消除. 但是后续该技术没有充分的发展.
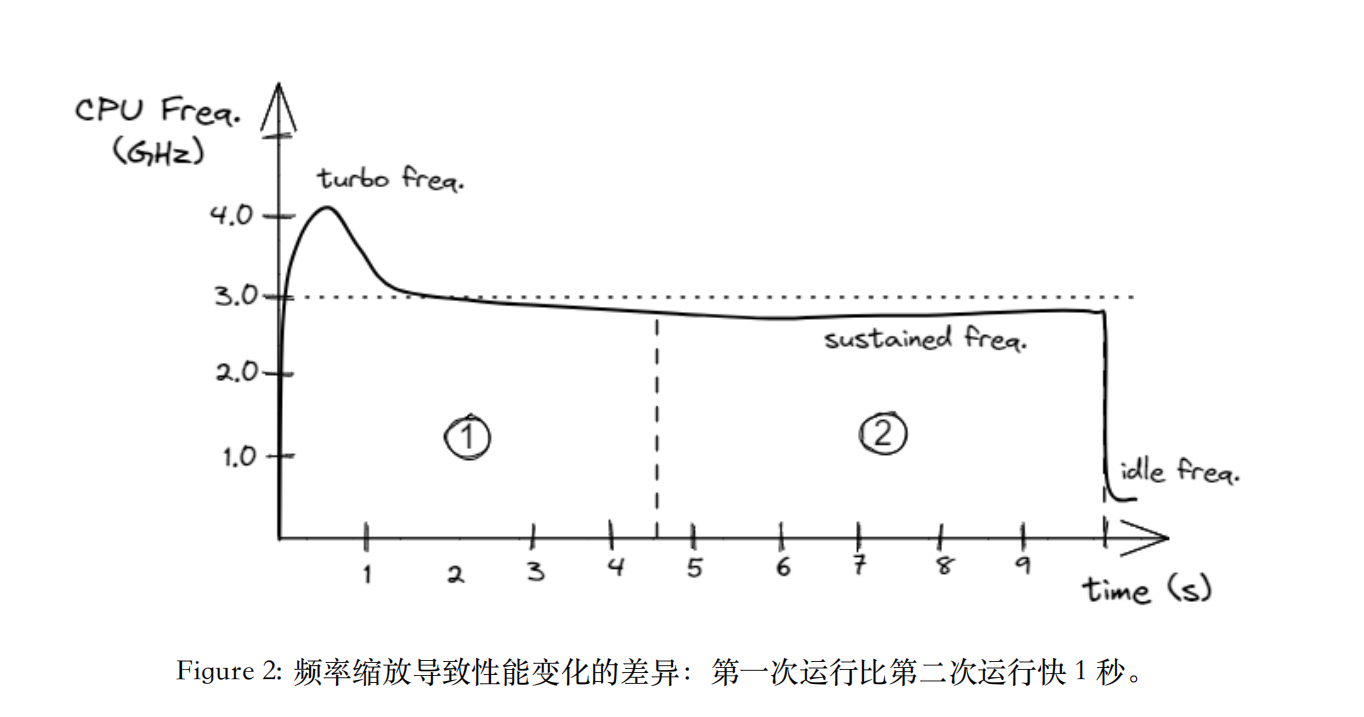
remark: 甚至开top/htop等监控工具也会影响性能分析的结果.
timer
现代 CPU 的高分辨率计时器有两种:
系统范围的高分辨率定时器: 例如 Linux 下的
clock_gettime(CLOCK_MONOTONIC, ...), 系统定时器具有纳秒级分辨率, 在所有 CPU 之间保持一致,并且与 CPU 频率无关。虽然系统定时器可以返回纳秒精度的时间戳,但由于通 过clock_gettime系统调用获取时间戳需要很长时间,因此不适合测量短时间内发生的事件。但是对于持续时 间超过一微秒的事件来说,这是可以接受的。在 C++ 中访问系统定时器的de facto标准是使用std::chrono.时间戳计数器(TSC): TSC 是 CPU 提供的一个寄存器, TSC 是单调的, 并且具有恒定的速率,即不考虑频率变化. 每个 CPU 都有自己的 TSC,它只是已经过去的参考周期数. 适用于持续时间从纳秒到一分钟的短事件的测量. 可以使用编译器内置函数
__rdtsc()来获取 TSC 的值, 如 Listing 25所示,该函数在底层使用RDTSC汇编指令。有关使用RDTSC汇编指令对代码进行基准测试的更低级别的详细信息, 可以参考白皮书. 调用该函数的开销大约为 20 个 CPU 周期. 而clock_gettime调用的开销大约为数百个 CPU 周期.
CPU Architecture Overview
ISA 和 流水线之类的基础知识这里懒得写了.
ILP
指令级并行(Instruction-Level Parallelism, ILP)是指在单个处理器内同时执行多条指令的能力。ILP 的目标是通过利用处理器的多个执行单元来提高指令吞吐量,从而提升整体性能。
乱序执行
在流水线中, 由于各条指令顺序进入, 后续指令若发生各种冲突或者依赖关系, 很有可能会导致流水线中被插入气泡, 或者流水线被清空.
现代cpu通常会通过某些硬件或者算法来实现, 比如硬件上的计分板(Scoresboarding), 或者更复杂的 Tomasulo 算法. 计分板的大小会影响程序查询独立指令的最大位置. 当某两条指令在相邻时钟周期会有依赖时, cpu会调度后续的独立指令先执行, 以此减少气泡.
super-scalar
超标量(Superscalar)是一种处理器设计技术, 允许在单个时钟周期内同时发射多条指令到多个执行单元. 通过这种方式, 超标量处理器能够提高指令级并行性(ILP), 从而提升整体性能.
超标量和乱序执行在现代cpu中通常是结合在一起的, 在部分cpu中, 这样的调度负担会被交给编译器来完成, 这被称为 VLIW (Very Long Instruction Word).
分支预测
- 无条件跳转和直接调用:它们最容易预测,因为它们总是被执行并且每次都以相同的方向执行。
- 条件分支:它们有两个潜在的结果:被执行或不被执行。被执行的分支可以向前或向后跳转。前向条件分支通常用于生成if-else语句,其不被执行的可能性很高,因为通常表示错误检查代码。后向条件跳转经常出现在循环中,并用于转到循环的下一次迭代;此类分支通常被执行。
- 间接调用和跳转:它们具有许多目标。间接跳转或间接调用可以生成switch语句、函数指针或virtual函数。函数返回也值得关注,因为它也有许多潜在的目标。
大多数分支预测类似于cache, 使用局部和全局历史来预测分支的结果.: 大多数预测算法基于分支的先前结果。分支预测单元(BPU)的核心是分支目标缓冲区(BTB),它为每个分支缓存 目标地址。预测算法每个周期都要查询 BTB,以生成下一个要提取指令的地址。CPU 使用该新地址提取下一个指令 块。如果在当前提取块中没有识别出分支,则提取的下一个地址将是下一个顺序对齐的提取块(顺序提取)。
这个和TLB有点像, TLB是cache虚拟地址到物理地址的映射, BTB是cache分支指令到目标地址的映射. 可以说cache是一种广义的预测技术.
局部性原理:
- 时间相关性:分支的解决方式可能是下次执行时解决方式的很好的预测器。这也称为局部相关性。
- 空间相关性:几个相邻的分支可能以高度相关的方式解决(执行的首选路径)。这也称为全局相关性。
基于统计: 一些分支具有偏向行为。一个示例是循环分支。如果分支具有循环行为,则可以使用专用的循环预测器进行预测,该预测器将记住循环通常执行的迭代次数。
multi-core
hyper-threading
由于多个独立程序的指令之间通常没有依赖关系, 因此可以在一个程序无法找到足够的独立指令来填充整个流水线的时候, 执行另一个程序的指令来提高资源利用率. 最常见的就是从内存加载较大数据的时候. 然后切换不同程序的指令的时候会面对刷新程序寄存器, TLB与cache互相污染等问题, 最终资源竞争导致性能下降.
除此之外超线程会导致程序性能分析产生巨大的困难, 特别是云服务商只提供线程级资源控制, 而非物理的核心的分配
异构核心
目前cpu涉及中已经出现了异构核心的设计, 比如Intel的P核和E核, 以及手机中的大核小核设计. 但是通常会面临一些问题, 比如操作系统对程序的调度. 有些指令集只能在大核上执行, 这会导致程序无法充分利用小核的资源.
cache
在实际的程序中, 许多程序由于良好的局部性, 在一段时间内对内存的操作会集中在某个地址附近的区域中, 因此为了减少内存访问延迟, 用延迟较低的高速内存来临时存储这些数据是非常有用的.
cache 结构
为了减少复杂性, 尽管现代 CPU 可能有多级缓存, 但通常一层缓存的抽象是足够的. 典型的 CPU 可能有三级缓存: L1, L2, L3. 其中 L1 最小且最快, L3 最大且最慢. L1 和 L2 通常是每个核心私有的, 而 L3 通常是多个核心共享的. 可以通过lstopo等工具查看 CPU 的缓存层次结构.
L1 cache通常被涉及为两个独立的缓存: 一个用于指令(i-cache), 另一个用于数据(d-cache).
缓存具有最小的单位, 被称为缓存行. 一般缓存行的大小为64 bytes.
缓存非常常见, 比如内存管理单元(MMU)中的 TLB (Translation Lookaside Buffer) 也是一种缓存, 用于缓存虚拟地址到物理地址的映射. 它也具有最小的单位, 通常是4KB的页面大小. 如果程序有非常高的内存需求, 可以调整页面大小, 使用大页(huge page)来减少 TLB 未命中的概率.
通常缓存中的缓存行是通过组相联映射(set-associative mapping)来组织的. 具体来说, 缓存被划分为多个集合(set), 每个集合包含多个缓存行(way). 当 CPU 需要访问某个内存地址时, 会根据地址的一部分来确定该地址映射到哪个集合, 然后在该集合中查找对应的缓存行.
当缓存未命中时, 通常会使用某种替换策略来决定哪个缓存行被替换出去. 常见的替换策略包括最近最少使用(LRU), 或者随机挑选一个缓存行进行替换. 并且且在写操作时, 可能会使用写回(write-back)或者直写(write-through)策略来处理缓存行的更新. 除此之外, 对于集合关联映射缓存, 新的缓存块只能放入其映射的集合中, 这可能会导致冲突未命中(conflict miss).
通常的缓存缺失的分类有三种:
- 冷启动未命中(cold miss): 当数据第一次被访问时, 由于缓存中没有该数据, 导致的未命中.
- 冲突未命中(conflict miss): 由于缓存的组相联映射限制, 多个数据地址映射到同一个集合, 导致的未命中.
- 容量未命中(capacity miss): 当缓存容量不足以存储所有需要的数据时, 导致的未命中.
conflict miss 和 bank conflict 的比较:
相似点
- 资源划分与访问局限:两者都把大资源划分为多个子单元(缓存的集合 / 存储器或寄存器的bank),每次访问只能作用到特定子单元,从而引入“访问位置受限”的问题。
- 冲突导致性能下降:如果多个并发或频繁访问的请求集中映射到同一子单元,就会发生冲突(cache 的 conflict miss 或 memory bank 的 bank conflict),导致未命中、等待或序列化访问,从而降低性能。
- 缓解策略相似:提高并行度(增加way数或bank数)、改变映射方式(hash、重映射)、重排数据布局、使用缓冲/队列(victim cache、request queue)等,都是常见的缓解方法。
主要区别
- 问题的发生场景:
- Cache conflict miss(集合冲突)通常是由程序的地址访问模式与缓存地址映射(index)之间的固定映射关系引起,是时间上和空间上访问的长期效果(第二次访问已经不在缓存中即为miss)。
- Bank conflict 多发生在并行或同时发起的多个访问(如 SIMD/GPU、内存控制器或多端口存储器场景),是并发访问导致的资源序列化或延迟。也会在时序上表现为需要排队或延迟完成。
- 后果表现:
- Cache 冲突表现为 miss(需要去更低层次存储取数据),带来更高的访问延迟和带宽成本。
- Bank conflict 通常是延迟增加(访问被序列化),但不一定导致数据从更下级介质加载(除非同时伴随缓存miss)。
- 触发粒度与机制:
- Cache 是按照块(block/line)和set映射,替换策略决定何时驱逐;冲突 miss 与替换策略和历史访问有关。
- Bank conflict 与同时到达不同地址但映射到同一bank的并发请求有关,硬件通常通过arbiter、队列或重排来处理。
举例对比
- 在一个4-way set-associative cache 中,如果多个常访问的地址都映射到同一 set 且超过4个,会产生 conflict miss(即便整个cache里有空余行)。
- 在GPU中,如果一个warp的多条内存请求对应到同一DRAM bank,内存控制器会把这些请求串行化,导致bank conflict,从而降低吞吐。
prefetching
预取(prefetching)是一种通过提前加载数据到缓存中来减少内存访问延迟的技术. 预取可以是硬件实现的, 也可以是软件实现的.
主存
主存(Main Memory)通常指计算机系统中的随机存取存储器(RAM), 它是CPU可以直接访问的存储器. 主存的速度远低于CPU缓存.
cpu访问主存首先需要经过内存控制器(Memory Controller Unit, MCU), MCU负责管理主存的读写操作, 包括地址映射, 刷新等工作. 现代CPU通常集成了MCU, 以减少访问延迟. 过去MCU通常是北桥芯片组的一部分.
北桥芯片组(Northbridge)是计算机主板上的一个重要组件, 负责连接CPU与高性能设备, 如内存和图形卡. 北桥芯片组通常处理高速数据传输, 并管理CPU与内存之间的通信. 现代计算机中, 北桥的功能已经逐渐被集成到CPU内部, 以提高性能和减少延迟. 南桥芯片组(Southbridge)则负责连接较低速的外设, 如硬盘, USB 设备等. 主要负责I/O操作和PCIE扩展槽, usb等设备的管理.
内存分为DDR与HBM两种主要类型. DDR是传统的内存类型, 通过内存总线与MCU连接. HBM是一种新型的内存类型, 通过堆叠芯片, 通常用于gpu等高性能计算设备中.
值得一提的是,DRAM 芯片需要定期刷新其内存单元。这是因为位值被存储为微小电容器上的电荷存在,所以它可能会随着时间的推移失去电荷。为了防止这种情况发生,有特殊的电路读取每个单元并将其写回,有效地恢复电容器的电荷。当 DRAM 芯片处于刷新过程中时,它不会响应内存访问请求。
通常内存会被分组, 每个组被称为一个rank. 每个rank包含多个内存芯片.
内存的width定义了每个DRAM芯片的总线宽度. 每个rank的总线宽度通常为64 bits(8 bytes).
通道(channel)是指内存控制器与内存模块之间的独立数据传输路径. 通过增加通道数量, 可以提高内存带宽. 服务器通常有4或8通道.
内存频率是指内存模块的工作速度, 通常以MHz为单位. 内存频率越高, 数据传输速度越快. 内存带宽可以直接用内存频率乘以通道数和每个通道的宽度来计算. 比如DDR4, 2400MHz, 4通道, 则带宽为 2400 * 4 * 8 = 76.8 GB/s. (每通道8字节).
为了提高内存通道的利用率, 通过将一个page中的相邻地址映射到不同的内存通道, 以此来实现并行访问. 这种技术被称为内存交错(memory interleaving).
虚拟内存(virtual memory)
虚拟内存是一种操作系统和硬件共同实现为进程提供逻辑上独立的内存空间的技术. 每个进程都认为自己拥有连续的内存地址空间, 而实际上这些地址可能被映射到物理内存的不同位置, 甚至被存储在磁盘上. 实现虚拟内存的关键组件是内存管理单元(MMU)和页表(page table). MMU负责将虚拟地址转换为物理地址, 页表存储了虚拟地址到物理地址的映射关系.
address translation
通常64位系统的虚拟地址空间中, 52位用作地址转换, 12位用作页内偏移(offset). 这样可以支持4KB的页面大小(2^12 = 4096 bytes). 页内偏移不需要再次转换, 直接加到物理地址上即可.
通常页表也可以进行嵌套. 通常实现方式是将52位地址继续切分.
以2级页表为例, 最高的16位通常不使用, 接下来的 16 位作为第一级页表的索引, 再接下来的 20 位作为第二级页表的索引, 最后的 12 位作为页内偏移. 这样每个页表可以包含 2^20 = 1,048,576 个条目.
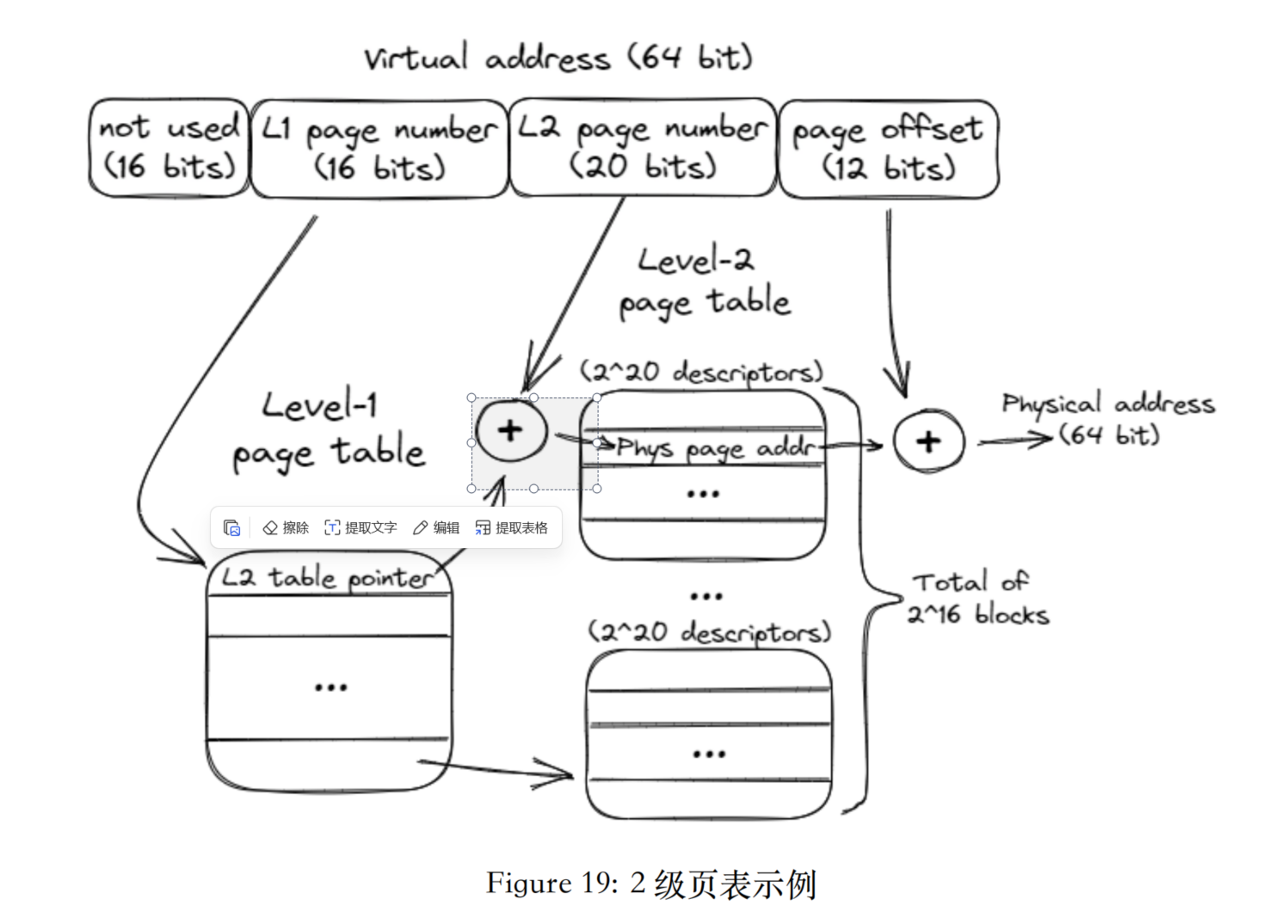
例子: 现在有一个虚拟地址. 首先查询页根的地址. 也就找到了第一级页表的地址. 然后使用虚拟地址的第一级索引部分, 找到第一级页表中的对应条目, 该条目储存的是第二级页表的地址. 接着使用虚拟地址的第二级索引部分, 找到第二级页表中的对应条目, 该条目储存的是物理页框的地址. 最后, 将物理页框地址与虚拟地址的页内偏移部分相加, 得到最终的物理地址.
TLB(Translation Lookaside Buffer)
TLB 是一种缓存, 用于存储最近使用的虚拟地址到物理地址的映射. 当 CPU 需要访问某个虚拟地址时, 首先会查询 TLB, 如果命中则可以快速获取物理地址, 否则需要访问页表进行转换, 这会带来较高的延迟.
huge page
Huge Page 是一种使用较大页面大小的虚拟内存技术. 传统的页面大小通常为4KB, 而 Huge Page 的大小可以是2MB或1GB. 使用 Huge Page 可以减少页表的层级, 降低 TLB 未命中的概率, 从而提高内存访问性能.
例如2MB的Huge Page使用21位作为页内偏移, 可以减轻TLB的压力. 然后较大的页面可能会导致内存碎片的问题, 因为分配和释放大块内存可能会留下无法使用的小块内存区域.
性能分析术语
retired v.s. excuted
由于现代cpu中的分支预测的存在, 相当多的指令是被推测执行的, 这导致当分支预测错误时指令需要重新被执行. 当一条指令被确保被正确的执行后, 它被称为retired, 因此retired的指令通常会比excuted指令更多.
然而也有特例, 部分指令在cpu前端被解析, 而不需要真正被执行, 这种情况下retired指令会多余excuted指令.
编译器优化报告
大部分现代编译器都支持生成优化报告. 这里看一个好玩的例子:
// unvec.cpp
void
unvec(
float* a,
float* b,
float* c
) {
for (int i = 1; i < N; i++) {
a[i] = c[i-1];
c[i] = b[i];
}
}
// vec.cpp
void
vec(
float* a,
float* b,
float* c
) {
for (int i = 1; i < N; i++) {
c[i] = b[i];
a[i] = c[i-1];
}
}
g++ -O3 -S -march=core-avx2 unvec.cpp -o unvec.s
g++ -O3 -S -march=core-avx2 vec.cpp -o vec.s
# unvec.s
.L3:
vmovss -4(%rdx,%rax,4), %xmm0
vmovss %xmm0, (%rdi,%rax,4)
vmovss (%rsi,%rax,4), %xmm0
vmovss %xmm0, (%rdx,%rax,4)
incq %rax
cmpq %rax, %rcx
jne .L3
# vec.s
.L5:
vmovups (%rsi,%rax), %ymm1
vmovups %ymm1, (%rdx,%rax)
vmovups -4(%rdx,%rax), %ymm2
vmovups %ymm2, (%rcx,%rax)
addq $32, %rax
cmpq %r8, %rax
jne .L5
vmovss 是标量单精度浮点数的加载/存储指令, 而 vmovups 是向量化的指令, 可以一次加载/存储多个单精度浮点数. 通过改变语句的顺序, 编译器能够识别出循环中的数据依赖关系, 并应用向量化优化.
用-fopt-info-vec参数可以让编译器输出向量化的报告, 以确认向量化是否成功应用.
g++ -O3 -march=core-avx2 -fopt-info-vec vec.cpp -o vec
g++ -O3 -march=core-avx2 -fopt-info-vec unvec.cpp -o unvec
unvec.cpp:11:23: missed: couldn't vectorize loop
unvec.cpp:13:21: missed: not vectorized, possible dependence between data-refs *_4 and *_8
vec.cpp:11:23: optimized: loop vectorized using 32 byte vectors
vec.cpp:11:23: optimized: loop versioned for vectorization because of possible aliasing
vec.cpp:11:23: optimized: loop vectorized using 16 byte vectors